Toxic Comment Classification

This post presents our solution for Toxic Comment Classification Challenge hosted on Kaggle by Zigsaw. This solution ranked 13th on the private leaderboard.
Identify and Classify Toxic Online Comments
Discussing things you care about can be difficult. The threat of abuse and harassment online means that many people stop expressing themselves and give up on seeking different opinions. Platforms struggle to effectively facilitate conversations, leading many communities to limit or completely shut down user comments.
So, in this competition on Kaggle, the challenge was to build a multi-headed model that’s capable of detecting different types of of toxicity like threats, obscenity, insults, and identity-based hate better than Perspective’s current models. A dataset of comments from Wikipedia’s talk page edits was provided.
Data Overview
The dataset used was Wikipedia corpus dataset which was rated by human raters for toxicity. The corpus contains comments from discussions relating to user pages and articles dating from 2004-2015.
The comments are to be tagged in the following six categories -
- toxic
- severe_toxic
- obscene
- threat
- insult
- identity_hate
Train and Test Data
The training data contains a row per comment, with an id, the text of the comment, and 6 different labels that we have to predict.
import pandas as pd
import numpy as np
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')
print('Train shape: ', train_df.shape)
print('Test shape: ', test_df.shape)
Train shape: (159571, 8)
Test shape: (153164, 2)
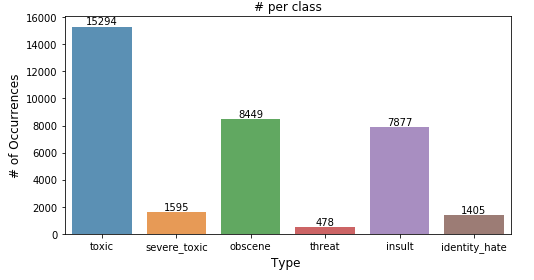
The training dataset is highly imbalanced with about 1,43,346 clean comments and only 16,225 comments with toxicity as shown below - .
Train Data after Basic Preprocessing and Cleaning
| ID | Comment Text |
|---|---|
| 0 | explanation why the edits made under my userna… |
| 1 | d aww ! he matches this background colour i am… |
| 2 | hey man i am really not trying to edit war it … |
| 3 | more i cannot make any real suggestions on im… |
| 4 | you sir are my hero any chance you remember wh… |
Test Data after Basic Preprocessing and Cleaning
| ID | Comment Text |
|---|---|
| 0 | yo bitch ja rule is more succesful then you wi… |
| 1 | = = from rfc = = the title is fine as it is imo |
| 2 | = = sources = = zawe ashton on lapland |
| 3 | if you have a look back at the source the inf… |
| 4 | i do not anonymously edit articles at all |
Cleaning Data
Pre-processing includes removing special symbols and punctuations from comments, converting to upper-case characters to lower case. The preprocessed comments were converted to fixed-length sequences by either truncating or padding with zeros. We can also perform stemming and lemmatization on the comments, but they are not effective when using deep learning architectures.
def cleanData(text, stemming=False, lemmatize=False):
text = text.lower().split()
text = " ".join(text)
text = re.sub(r"[^A-Za-z0-9^,!.\/'+\-=]", " ", text)
text = re.sub(r"what's", "what is ", text)
text = re.sub(r"\'s", " ", text)
text = re.sub(r"\'ve", " have ", text)
text = re.sub(r"can't", "cannot ", text)
text = re.sub(r"n't", " not ", text)
text = re.sub(r"i'm", "i am ", text)
text = re.sub(r"\'re", " are ", text)
text = re.sub(r"\'d", " would ", text)
text = re.sub(r"\'ll", " will ", text)
text = re.sub(r",", " ", text)
text = re.sub(r"\.", " ", text)
text = re.sub(r"!", " ! ", text)
text = re.sub(r"\/", " ", text)
text = re.sub(r"\^", " ^ ", text)
text = re.sub(r"\+", " + ", text)
text = re.sub(r"\-", " - ", text)
text = re.sub(r"\=", " = ", text)
text = re.sub(r"'", " ", text)
text = re.sub(r"(\d+)(k)", r"\g<1>000", text)
text = re.sub(r":", " : ", text)
text = re.sub(r" e g ", " eg ", text)
text = re.sub(r" b g ", " bg ", text)
text = re.sub(r" u s ", " american ", text)
text = re.sub(r"\0s", "0", text)
text = re.sub(r" 9 11 ", "911", text)
text = re.sub(r"e - mail", "email", text)
text = re.sub(r"j k", "jk", text)
text = re.sub(r"\s{2,}", " ", text)
if stemming:
st = PorterStemmer()
txt = " ".join([st.stem(w) for w in text.split()])
if lemmatize:
wordnet_lemmatizer = WordNetLemmatizer()
txt = " ".join([wordnet_lemmatizer.lemmatize(w) for w in text.split()])
return text
Exploring Train Data
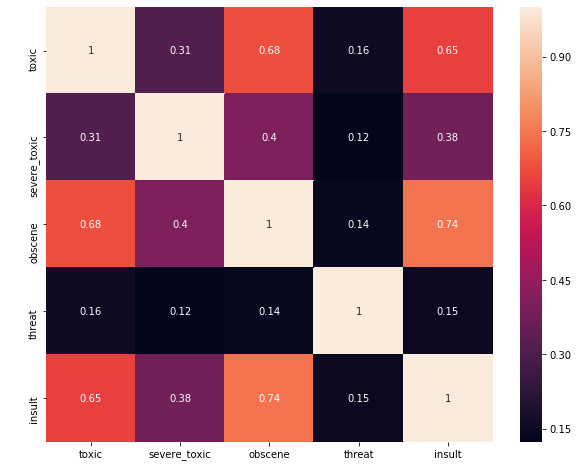
Correlation between Output Classes
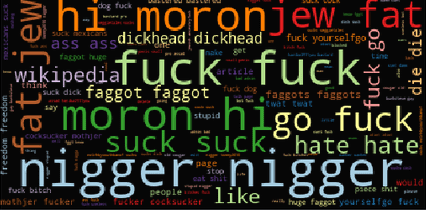
Words frequently occurring in Toxic Comments

Words frequently occurring in Severe Toxic Comments

Words frequently occurring in Threat Comments

Words frequently occurring in Insult Comments
Our Solution
The final solution consists of ensemble of several machine learning models -
- Attention with Bidirectional LSTM
- Bidirectional LSTM with Pre-Post Input Text
- Bidirectional GRU with derived features
- Capsule Network
- CNN based on DeepMoji Architecture
- CNN + GRU
- DeepMoji Architecture
- Character Level Hierarchical Network
- Ensemble of Logistic Regression and SVM
- 2D CNN
- LightGBM
Each model was trained using 10 fold validation with proper hyperparameter tuning. Each model was fed with starting 150 words along with 150 words from the end of the comments. This provided a significant boost in the performance since many comments were toxic at the end.
Finally, we used LightGBM, Catboost and simple weighted averaging for stacking these models, thus creating a three-layer ensemble of models.
Embeddings Used
Various pre-trained embeddings were used to create diverse models -
- GloVe
- fastText
- word2vec
- Byte-Pair Encoded subword embeddings (BPE)
Results
- The overall model got a ROC AUC score of 0.9874 on private LB.
- Preprocessing was not much impactful and did not significantly improve the score of any model.
- RNN models were significantly better than CNN models.
- The best model was recurrent capsule network followed by DeepMoji and CNN-GRU.
- Adding attention layer to RNN models boosted their score.
- Logistic regression and LightGBM models had much lower scores but provided diversity.
- Some input samples were toxic only in the last few words. Thus, training each model on ending 150 words in addition to starting 150 words improved their performance.
Thank You!
Important Links
GitHub Repository
Toxic Comment Classification Challenge - Kaggle
RNN for Text Classification
Attention based RNN
RNN + CNN
Very Deep CNN
Deep Pyramid CNN
Hierarchical Attention Network
GloVe
fastText
BPE
EDA
Summary of our solution by Mohsin

.png)